
九、HBase开发实例下
大纲:
演示HBase的java代码编写
使用eclipse创建一个hbase_study2工程并添加对应的jar包
创建包:com.jkb.hbase
追加插入
// 追加插入(将原有value的后面追加新的value,如原有value=a追加value=bc则最后的value=abc)
public static void appendData(String tableName, String rowKey, String columnFamily, String column, String value)
throws IOException {
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(tableName));
// 通过rowkey创建一个append对象
Append append = new Append(Bytes.toBytes(rowKey));
// 在append对象中设置列族、列、值
append.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
// 追加数据
table.append(append);
// 关闭资源
table.close();
conn.close();
}
符合条件后插入数据
// 符合条件后添加数据(只能针对某一个rowkey进行原子操作)
public static boolean checkAndPut(String tableName, String rowKey, String columnFamilyCheck, String columnCheck, String valueCheck, String columnFamily, String column, String value) throws IOException {
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(tableName));
// 设置需要添加的数据
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
// 当判断条件为真时添加数据
boolean result = table.checkAndPut(Bytes.toBytes(rowKey), Bytes.toBytes(columnFamilyCheck),
Bytes.toBytes(columnCheck), Bytes.toBytes(valueCheck), put);
// 关闭资源
table.close();
conn.close();
return result;
}
符合条件后删除数据
// 符合条件后刪除数据(只能针对某一个rowkey进行原子操作)
public static boolean checkAndDelete(String tableName, String rowKey, String columnFamilyCheck, String columnCheck,
String valueCheck, String columnFamily, String column) throws IOException {
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(tableName));
// 设置需要刪除的delete对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(columnFamilyCheck), Bytes.toBytes(columnCheck));
// 当判断条件为真时添加数据
boolean result = table.checkAndDelete(Bytes.toBytes(rowKey), Bytes.toBytes(columnFamilyCheck), Bytes.toBytes(columnCheck),
Bytes.toBytes(valueCheck), delete);
// 关闭资源
table.close();
conn.close();
return result;
}
计数器
// 计数器(amount为正数则计数器加,为负数则计数器减,为0则获取当前计数器的值)
public static long incrementColumnValue(String tableName, String rowKey, String columnFamily, String column, long amount)
throws IOException {
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(tableName));
// 计数器
long result = table.incrementColumnValue(Bytes.toBytes(rowKey), Bytes.toBytes(columnFamily), Bytes.toBytes(column), amount);
// 关闭资源
table.close();
conn.close();
return result;
}
十、HBase过滤器
大纲:
讲解hbase过滤器
hbase过滤器代码演示
HBase为筛选数据提供了一组过滤器,通过这个过滤器可以在HBase中数据的多个维度(行、列、数据版本)上进行对数据的筛选操作,也就是说过滤器最终能够筛选的数据能够细化到具体的一个存储单元格上(由行键、列名、时间戳定位)。通常来说,通过行键、值来筛选数据的应用场景较多。需要说明的是,过滤器会极大地影响查询效率。所以,在数据量较大的数据表中,应尽量避免使用过滤器。
下面介绍一些常用的HBase内置过滤器的用法:
1、RowFilter:筛选出匹配的所有的行。使用BinaryComparator可以筛选出具有某个行键的行,或者通过改变比较运算符(下面的例子中是CompareFilter.CompareOp.EQUAL)来筛选出符合某一条件的多条数据,如下示例就是筛选出行键为row1的一行数据。
// 筛选出匹配的所有的行
Filter rf = new RowFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("row1")));
2、PrefixFilter:筛选出具有特定前缀的行键的数据。这个过滤器所实现的功能其实也可以由RowFilter结合RegexComparator来实现,不过这里提供了一种简便的使用方法,如下示例就是筛选出行键以row为前缀的所有的行。
// 筛选匹配行键的前缀成功的行
Filter pf = new PrefixFilter(Bytes.toBytes("row"));
3、KeyOnlyFilter:这个过滤器唯一的功能就是只返回每行的行键,值全部为空,这对于只关注于行键的应用场景来说非常合适,这样忽略掉其值就可以减少传递到客户端的数据量,能起到一定的优化作用。
// 返回所有的行键,但值全是空 Filter kof = new KeyOnlyFilter();
4、RandomRowFilter:按照一定的几率(<=0会过滤掉所有的行,>=1会包含所有的行)来返回随机的结果集,对于同样的数据集,多次使用同一个RandomRowFilter会返回不同的结果集,对于需要随机抽取一部分数据的应用场景,可以使用此过滤器。
// 随机选出一部分的行 Filter rrf = new RandomRowFilter((float) 0.8);
5、InclusiveStopFilter:扫描的时候,我们可以设置一个开始行键和一个终止行键,默认情况下,这个行键的返回是前闭后开区间,即包含起始行,但不包含终止行。如果我们想要同时包含起始行和终止行,那么可以使用此过滤器。
// 包含了扫描的上限在结果之内
Filter isf = new InclusiveStopFilter(Bytes.toBytes("row1"));
6、FirstKeyOnlyFilter:如果想要返回的结果集中只包含第一列的数据,那么这个过滤器能够满足要求。它在找到每行的第一列之后会停止扫描,从而使扫描的性能也得到了一定的提升。
// 筛选出每行的第一个单元格 Filter fkof = new FirstKeyOnlyFilter();
7、ColumnPrefixFilter:它按照列名的前缀来筛选单元格,如果我们想要对返回的列的前缀加以限制的话,可以使用这个过滤器。
// 筛选出前缀匹配的列
Filter cpf = new ColumnPrefixFilter(Bytes.toBytes("qual1"));
8、ValueFilter:按照具体的值来筛选单元格的过滤器,这会把一行中值不能满足的单元格过滤掉,如下面的构造器,对于每一行的一个列,如果其对应的值不包含ROW2_QUAL1,那么这个列就不会返回给客户端。
// 筛选某个(值的条件满足的)特定的单元格
Filter vf = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("ROW2_QUAL1"));
9、ColumnCountGetFilter:这个过滤器在遇到一行的列数超过我们所设置的限制值的时候,结束扫描操作。
// 如果突然发现一行中的列数超过设定的最大值时,整个扫描操作会停止 Filter ccf = new ColumnCountGetFilter(2);
10、SingleColumnValueFilter:用一列的值决定这一行的数据是否被过滤,可对它的对象调用setFilterIfMissing方法,默认的参数是false。其作用是,对于咱们要使用作为条件的列,如果参数为true,这样的行将会被过滤掉,如果参数为false,这样的行会包含在结果集中。
// 将满足条件的列所在的行过滤掉
SingleColumnValueFilter scvf = new SingleColumnValueFilter(
Bytes.toBytes("colfam1"),
Bytes.toBytes("qual2"),
CompareFilter.CompareOp.NOT_EQUAL,
new SubstringComparator("BOGUS"));
scvf.setFilterIfMissing(true);
11、SingleColumnValueExcludeFilter:这个过滤器与第10种过滤器唯一的区别就是,作为筛选条件的列,其行不会包含在返回的结果中。
12、SkipFilter:这是一种附加过滤器,其与ValueFilter结合使用,如果发现一行中的某一列不符合条件,那么整行就会被过滤掉。
// 发现某一行中的一列需要过滤时,整个行就会被过滤掉 Filter skf = new SkipFilter(vf);
13、WhileMatchFilter:使用这个过滤器,当遇到不符合设定条件的数据的时候,整个扫描结束。
// 当遇到不符合过滤器rf设置的条件时,整个扫描结束 Filter wmf = new WhileMatchFilter(rf);
14. FilterList:可以用于综合使用多个过滤器。其有两种关系: Operator.MUST_PASS_ONE表示关系AND,Operator.MUST_PASS_ALL表示关系OR,并且FilterList可以嵌套使用,使得我们能够表达更多的需求。
// 综合使用多个过滤器,AND和OR两种关系 List<Filter> filters = new ArrayList<Filter>(); filters.add(rf); filters.add(vf); FilterList fl = new FilterList(FilterList.Operator.MUST_PASS_ALL,filters);
下面给出一个使用RowFilter过滤器的完整示例:
public class HBaseFilter {
private static final String TABLE_NAME = "table1";
public static void main(String[] args) throws IOException {
// 设置配置
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "localhost");
conf.set("hbase.zookeeper.property.clientPort", "2181");
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(TABLE_NAME));
// 创建一个扫描对象
Scan scan = new Scan();
// 创建一个RowFilter过滤器
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("abc")));
// 将过滤器加入扫描对象
scan.setFilter(filter);
// 输出结果
ResultScanner results = table.getScanner(scan);
for (Result result : results) {
for (Cell cell : result.rawCells()) {
System.out.println(
"行键:" + new String(CellUtil.cloneRow(cell)) + "\t" +
"列族:" + new String(CellUtil.cloneFamily(cell)) + "\t" +
"列名:" + new String(CellUtil.cloneQualifier(cell)) + "\t" +
"值:" + new String(CellUtil.cloneValue(cell)) + "\t" +
"时间戳:" + cell.getTimestamp());
}
}
// 关闭资源
results.close();
table.close();
conn.close();
}
}
我们知道,在伪分布式模式和完全分布式模式下的HBase是架构在HDFS之上的,因此完全可以将MapReduce编程框架和HBase结合起来使用。也就是说,将HBase作为底层存储结构,MapReduce调用HBase进行特殊的处理,这样能够充分结合HBase分布式大型数据库和MapReduce并行计算的优点。
HBase实现了TableInputFormatBase类,该类提供了对表数据的大部分操作,其子类TableInputFormat则提供了完整的实现,用于处理表数据并生成键值对。TableInputFormat类将数据表按照Region分割成split,即有多少个Regions就有多个splits,然后将Region按行键分成<key,value>对,key值对应与行键,value值为该行所包含的数据。
HBase实现了MapReduce计算框架对应的TableMapper类和TableReducer类。其中,TableMapper类并没有具体的功能,只是将输入的<key,value>对的类型分别限定为Result和ImmutableBytesWritable。IdentityTableMapper类和IdentityTableReducer类则是上述两个类的具体实现,其和Mapper类和Reducer类一样,只是简单地将<key,value>对输出到下一个阶段。
HBase实现的TableOutputFormat将输出的<key,value>对写到指定的HBase表中,该类不会对WAL(Write-Ahead Log)进行操作,即如果服务器发生故障将面临丢失数据的风险。可以使用MultipleTableOutputFormat类解决这个问题,该类可以对是否写入WAL进行设置。
为了能使Hadoop集群上运行HBase程序,还需要把相关的类文件引入Hadoop集群上,不然会出现ClassNotFoundException错误。其具体方法是可在hadoop的环境配置文件hadoop-env.sh中引入HBASE_HOME和HBase的相关jar包,或者直接将HBase的jar包打包到应用程序文件中。
下面这个例子是将MapReduce和HBase结合起来的WordCount程序,它首先从指定文件中搜集数据,进行统计计算,最后将结果存储到HBase中:
package com.hbase.demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
public class HBaseWordCount {
public static class hBaseMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for ( String w : words) {
word.set(w);
context.write(word, ONE);
}
}
}
public static class hBaseReducer extends TableReducer<Text, IntWritable, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
// Put实例化,每个词存一行
Put put = new Put(key.getBytes());
// 列族为content,列名为count,列值为单词的数目
put.addColumn("content".getBytes(), "count".getBytes(), String.valueOf(sum).getBytes());
context.write(NullWritable.get(), put);
}
}
// 创建HBase数据表
public static void createHBaseTable(String tableName) throws IOException {
// 配置HBse
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "localhost");
conf.set("hbase.zookeeper.property.clientPort", "2181");
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 创建一个数据库管理员
HBaseAdmin hAdmin = (HBaseAdmin) conn.getAdmin();
// 判断表是否存在
if (hAdmin.tableExists(tableName)) {
System.out.println("该数据表已存在,正在重新创建");
hAdmin.disableTable(tableName);
hAdmin.deleteTable(tableName);
}
// 创建表描述
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
// 在表描述里添加列族
tableDesc.addFamily(new HColumnDescriptor("content"));
// 创建表
hAdmin.createTable(tableDesc);
System.out.println("创建" + tableName + "表成功");
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 3) {
System.out.println("args error");
System.exit(0);
}
String input = args[0];
String jobName = args[1];
String tableName = args[2];
// 创建数据表
HBaseWordCount.createHBaseTable(tableName);
// 配置MapReduce(或者将hadoop和hbase的相关配置文件引入项目)
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "localhost:9000");
conf.set("mapred.job.tracker", "localhost:9001");
conf.set("hbase.zookeeper.quorum", "localhost");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set(TableOutputFormat.OUTPUT_TABLE, tableName);
// 配置任务
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(HBaseWordCount.class);
job.setMapperClass(hBaseMapper.class);
job.setReducerClass(hBaseReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TableOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(input));
//执行MR任务
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
十一、MapReduce开发实例下
大纲:
演示实例讲解
演示编写mapreduce实例
处理前数据
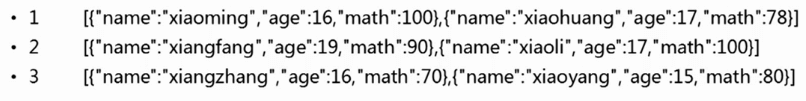
处理后数据
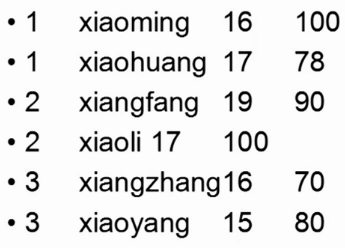
编写过程:
创建mapreduce3的工程
创建com.jkb.mapreduce包
创建OnlyMap类
public class OnlyMap{
public static class JMap extends Mapper<Object, Text, Text, Text>{
public static final String SP = "\t";
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException{
String[] lines = values.toString().split(SP);
if(lines.length == 2){
String clazz = lines[0];
String json = lines[1];
JSONArray jsonArray = JSONArray.fromObject(json);
int size = jsonArray.size();
for(int i = 0; i < size; i++){
String name = "";
String age = "";
String math = "";
JSONObject jsonObject = jsonArray.getJSONObject(i);
if(jsonObject.containKey("name")) name = jsonObject.getString("name");
if(jsonObject.containKey("age")) age = jsonObject.getString("age");
if(jsonObject.containKey("math")) math = jsonObject.getString("math");
StringBuffer buffer = new StringBuffer();
buffer.append(name);
buffer.append(SP);
buffer.append(age);
buffer.append(SP);
buffer.append(math);
context.write(new Text(clazz), new Text(buffer.toString()));
}
}
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException{
//args0 dst
//args1 out
//args2 splitMB
if(args.length != 3){
System.exit(0);
}
int splitMB = Integer.valueOf(args[2]);
String dst = args[0];
String out = args[1];
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.maxsize", String.valueOf(splitMB * 1024 * 1024));
conf.set("mapred.min.split.size", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", String.valueOf(SplitMB * 1024 * 1024));
//过时的方式
//DistributedCache.addFIleIoClassPath(new Path("/json_jar/commons-beanutils-1.8.0.jar"), conf);
//DistributedCache.addFIleIoClassPath(new Path("/json_jar/commons-collections-3.2.1.jar"), conf);
//DistributedCache.addFIleIoClassPath(new Path("/json_jar/commons-lang-2.4.jar"), conf);
//DistributedCache.addFIleIoClassPath(new Path("/json_jar/commons-logging-1.1.3.jar"), conf);
//DistributedCache.addFIleIoClassPath(new Path("/json_jar/ezmorph-1.0.6.jar"), conf);
//DistributedCache.addFIleIoClassPath(new Path("/json_jar/json-lib-2.4-jdk15.jar"), conf);
Job job = new Job(conf);
job.addFIleIoClassPath(new Path("/json_jar/commons-beanutils-1.8.0.jar"));
job.addFIleIoClassPath(new Path("/json_jar/commons-collections-3.2.1.jar"));
job.addFIleIoClassPath(new Path("/json_jar/commons-lang-2.4.jar"));
job.addFIleIoClassPath(new Path("/json_jar/commons-logging-1.1.3.jar"));
job.addFIleIoClassPath(new Path("/json_jar/ezmorph-1.0.6.jar"));
job.addFIleIoClassPath(new Path("/json_jar/json-lib-2.4-jdk15.jar"));
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(0);
job.setMapperClass(JMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setJarByClass(OnlyMap.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
}
}
将上述类打包成onlyMap.jar。上传到测试集群上。
将相应的jar包上传到hdfs上。

查看待处理的数据。

输入命令hadoop jar com.jkb.mapreduce.OnlyMap /test/map /test/out2 64
十二、HBase的Bulkload
HBase可以让我们随机的、实时的访问大数据,但是怎样有效的将数据导入到HBase呢?HBase有多种导入数据的方法,最直接的方法就是在MapReduce作业中使用TableOutputFormat作为输出,或者使用标准的客户端API,但是这些都不是非常有效的方法。
如果HDFS中有海量数据要导入HBase,可以先将这些数据生成HFile文件,然后批量导入HBase的数据表中,这样可以极大地提升数据导入HBase的效率。这就是HBase的Bulkload,即利用MapReduce作业输出HBase内部数据格式的表数据,然后将生成的StoreFiles直接导入到集群中。与使用HBase API相比,使用Bulkload导入数据占用更少的CPU和网络资源。两个表之间的数据迁移也可以使用这种方法。下面给出具体示例:
package com.hbase.demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.PutSortReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class HBaseBulk {
public static class bulkMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将输入数据用tab键分词
String[] values = value.toString().split("\t");
if (values.length == 2) {
// 设置行键、列族、列名和值
byte[] rowKey = Bytes.toBytes(values[0]);
byte[] family = Bytes.toBytes("content");
byte[] column = Bytes.toBytes("number");
byte[] colValue = Bytes.toBytes(values[1]);
// 将行键序列化作为mapper输出的key
ImmutableBytesWritable rowKeyWritable = new ImmutableBytesWritable(rowKey);
// 将put对象作为mapper输出的value
Put put = new Put(rowKey);
put.addColumn(family, column, colValue);
context.write(rowKeyWritable, put);
}
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.out.println("args error");
System.exit(0);
}
String input = args[0];
String output = args[1];
String jobName = args[2];
String tableName = args[3];
// 配置MapReduce(或者将hadoop的相关配置文件引入项目)
Configuration hadoopConf = new Configuration();
hadoopConf.set("fs.defaultFS", "localhost:9000");
hadoopConf.set("mapred.job.tracker", "localhost:9001");
Job job = Job.getInstance(hadoopConf, jobName);
job.setJarByClass(HBaseBulk.class);
job.setMapperClass(bulkMapper.class);
job.setReducerClass(PutSortReducer.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
FileInputFormat.addInputPath(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
// 配置HBase(或者将hbase的相关配置文件引入项目)
Configuration hbaseConf = HBaseConfiguration.create();
hbaseConf.set("hbase.zookeeper.quorum", "localhost");
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");
// 生成HFile
Connection conn = ConnectionFactory.createConnection(hbaseConf);
HTable table = (HTable) conn.getTable(TableName.valueOf(tableName));
HFileOutputFormat2.configureIncrementalLoad(job, table);
// 执行任务
job.waitForCompletion(true);
// 将HFile文件导入HBase
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(hbaseConf);
loader.doBulkLoad(new Path(output), table);
}
}
上述代码首先将HDFS中的数据文件通过MapReduce任务生成HFile文件,然后将HFile文件导入HBase数据表(该数据表已存在)。
Comments | 3 条评论
运营-子客
习惯好不错
赵忠印
楼主好高产啊
小十
@赵忠印 哈哈,伟大的会长~~~